Input and Output
Overview
Teaching: 10 min
Exercises: 5 minQuestions
How is input/output in the HPC clusters organized?
How do I optimize input/output in HPC environment?
Objectives
Sketch the storage structure of a generic, typical cluster
Understand the terms “local disk”, “IOPS”, “SAN”, “metadata”, “parallel I/O”
Cluster storage
Cluster Architecture
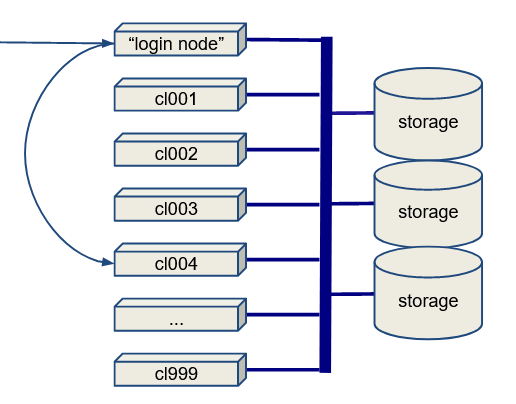
Here is the basic architecture of an HPC cluster:
- There is a login node (or maybe more than one).
- There might be a data transfer node (DTN), which is a login node specially designated for doing data transfers.
- There are a lot of compute nodes. The compute nodes may or may not have local disks.
- Most I/O goes to a storage array or SAN (Storage Array Network).
Broadly, you have two choices: You can do I/O to the node-local disk (if there is any), or you can do I/O to the SAN. Local disk suffers little or no contention but is inconvenient.
Local disk
What are the inconveniences of a local disk? What sort of work patterns suffer most from this? What suffers the least? That is, what sort of jobs can use local disk most easily?
Discussion
In a shared computing environment with a DRM running (e.g. Slurm) you cannot know in advance which machine will run your job, so you can’t stage the data needed onto the node in advance. Moving the input data onto the node and the output data off the node must be incorporated into the job script.
If you’re running a distributed-memory job that uses more than one node, then the data has to be distributed and collected from all the nodes, or else all I/O has to be done by a single node— which may become a bottleneck to performance.
Some distributed-memory programs use parallel I/O, which means that different processes may write to a single file at the same time. This is not possible with node-local storage since the nodes don’t share files.
Jobs that use a lot of temporary files which are discarded at the end of the job are very well-suited to node-local storage.
Jobs that make do many small I/O operations (e.g. writing detailed progress information to a log file) are very poorly suited to network storage (SAN), and so are well-suited to node-local storage by comparison.
Mixed use of node and network storage is also possible, e.g. reading data from the SAN but writing results to local disk before staging them back at the end of the calculation, or at infrequent intervals during the calculation.
Local disk performance depends on a lot of things. If you’re interested you can get an idea about Intel data center solid-state drives here.
For that particular disk model, sequential read/write speed is 3200/3200 MB/sec, It is also capable of 654K/220K IOPS (IO operations per second) for 4K random read/write.
Storage Array Network
Most input and output on a cluster goes through the SAN. There are many architectural choices made in constructing SAN.
- What technology? Lustre and GPFS are two important ones, used at ACENET and the Alliance.
- How many servers, and how many disks in each? What disks?
- How many MDS? MDS = MetaData Server. Things like
lsonly require metadata. Exactly what is handled by the MDS (or even if there is one) may depend on the technology chosen (e.g. Lustre, GPFS, …). - What switches connect the storage servers, and how many of them?
- Are things wired together with Ethernet, Infiniband, or something else? What’s the wiring topology?
- Where is there redundancy or failovers, and how much?
This is all the domain of the sysadmins, but what should you as the user do about input/output?
Programming input/output.
If you’re doing parallel computing you have choices about how you do input and output.
- One-file-per-process is reliable, portable and simple, but not great for checkpointing and restarting.
- Many small files on a SAN (or anywhere, really) leads to metadata bottlenecks. Most HPC filesystems assume no more than 1,000 files per directory.
- To have many different processes write to the same file at one time is called “parallel I/O”. MPI supports this via a specification called MPI-IO.
- Parallel I/O makes restarts simpler, but it must be written into the program, it can’t be “added on” trivially.
It also requires support from the underlying file system. (Luster and GPFS support it.) - High-level interfaces like NetCDF and HDF5 are highly recommended
- I/O bottlenecks:
- Disk read-write rate. May be alleviated by striping.
- Network bandwidth.
- Switch capacity.
- Metadata accesses (especially if there is only one MDS)
Measuring I/O rates
- Look into IOR
- Read this 2007 paper, Using IOR to Analyze the I/O performance for HPC Platforms
- Neither of these are things to do right this minute!
The most important part you should know is that the parallel filesystem is optimized for storing large shared files that may be accessible from many computing node. If used to store many small size files, it will perform poorly. As you may have been told in our new-user seminar, we strongly recommend that you do not to generate millions of small size files.
—– Takeaways:
- I/O is complicated. If you want to know what performs best, you’ll have to experiment.
- A few large IO operations are better than many small ones.
- A few large files are usually better than many small files.
- High-level interfaces (e.g. HDF5, netCDF) are your friends, but even they’re not perfect.
Moving data on and off a cluster
- “Internet” cabling varies a lot. 100Mbit/s widespread, 1Gbit becoming common, 10Gbit or more between most CC sites
- Remember, there are 8 bits in a byte. Pay careful attention to whether the number you are reading is bits or bytes!
- CANARIE is the Canadian research network. Check out their Network website
-
Firewalls sometimes the problem - security versus speed
- Filesystem at sending or receiving end often the bottleneck (SAN or simple disk)
- What are the typical disk I/O rates? See above! Highly variable!
Estimating transfer times
- How long to move a gigabyte at 100Mbit/s?
- How long to move a terabyte at 1Gbit/s?
Solution
Remember a byte is 8 bits, a megabyte is 8 megabits, etc.
- 1024 MByte/GByte * 8 bit/Byte / 100 Mbit/sec = 81 sec
- 1024 TByte/GByte * 8 bit/Byte / 1 Gbit/sec = 8192 sec, a little under 2 hours and 20 minutes
Remember these are “theoretical maximums”! There is almost always some other bottleneck or contention that reduces this!
- Restartable downloads (wget? rsync? Globus!)
- checksumming (md5sum) to verify the integrity of large transfers
Key Points