Programming GPUs with OpenMP
Overview
Teaching: 35 min
Exercises: 5 minQuestions
How to program GPU with OpenMP?
Objectives
Learn about tools available for programming GPU
Learn about programming GPU with openMP
Introduction to OpenMP Device Offload
- GPUs can deliver very high performance per compute node.
- Computing workloads are often accelerated by GPUs in HPC clusters.
The GPU Architecture
-
CPUs are designed to handle a wide-range of tasks quickly, but are limited in the number of tasks that can be running concurrently.
-
GPUs consist of thousands of smaller and more specialized processing units (cores).
Nvidia calls its parallel processing platform Compute Unified Device Architecture (CUDA).
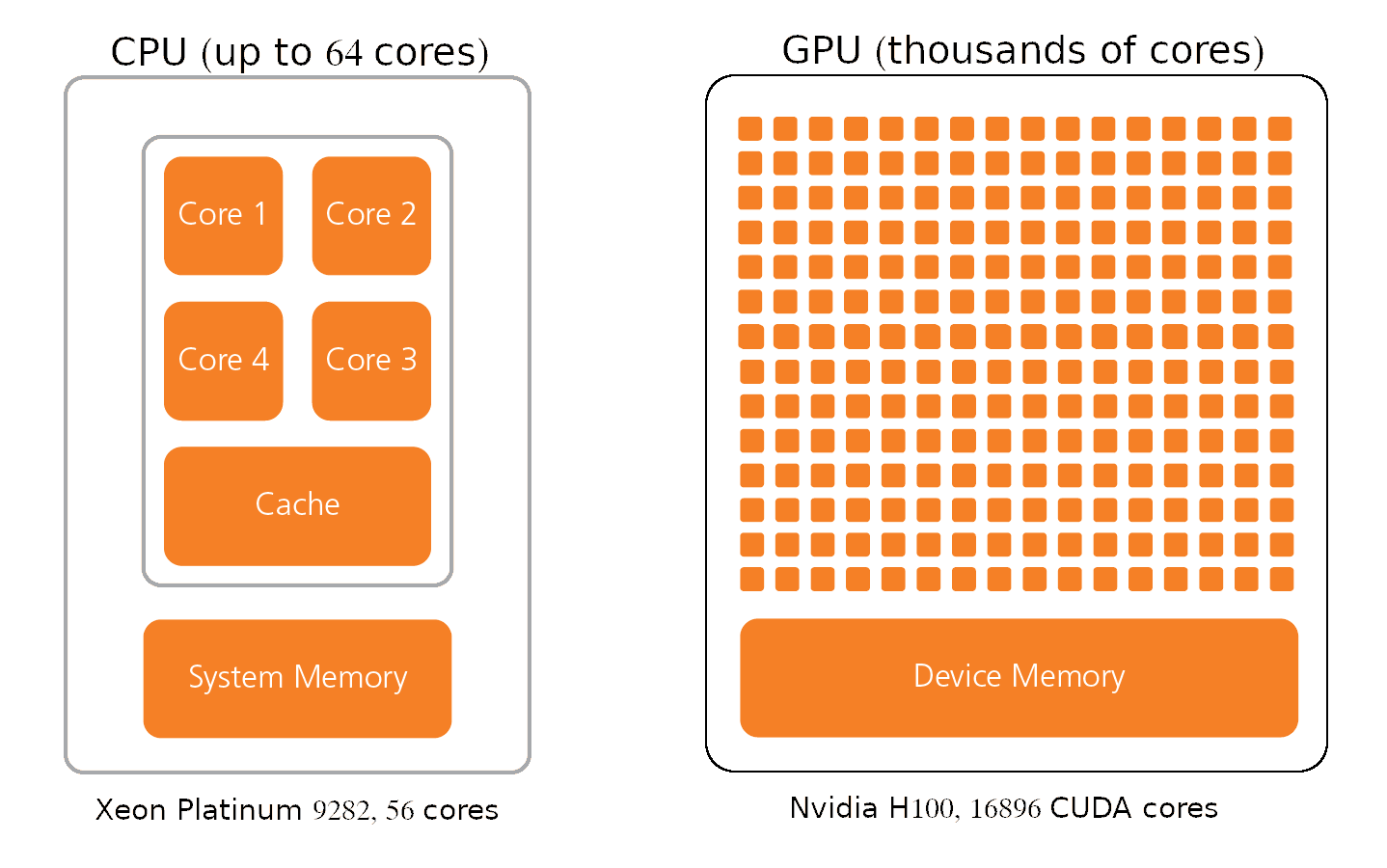
- Nvidia H100 GPUs
- up to 132 Streaming Multiprocessors
- 128 FP32 CUDA cores per SM
- total 16896 CUDA cores.
- Intel® Xeon® Platinum 9282
- 56 cores
- 1 AVX-512 vector unit per core can process 16 FP32 numbers at a time.
GPU architecture enables to process massive amounts of data simultaneously at extremely fast speeds.
Tools for Programming GPUs
There are several tools available for programming GPU.
- CUDA is NVIDIA-specific programming model and language. With CUDA, you can maximize your program performance. CUDA requires significant refactoring of existing C/C++ or Fortran code.
- PyCuDA. Gives access to CUDA functionality from Python code.
- OpenCL. Programs written in OpenCL can run on CPUs, GPUs, FPGAs, and other hardware accelerators. Very complex and hard to program, not widely used.
- OpenMP and OpenACC. Directive-based, offer a quick path to accelerated computing with less programming effort.
Read more about OpenMP on GPUs
Differences between OpenMP and OpenACC
- OpenMP approach is more prescriptive, programmers tell compiler explicitly where and how to parallelize the code
- OpenACC programs are more descriptive of parallelism and rely more on the compiler to implement the parallelism efficiently.
The OpenMP GPU programming model
GPU programming with OpenMP is based on a host-device model.

- The host is where the initial thread of a program begins to run.
- The host can be connected to one or more GPU devices.
- Each Device is composed of one or more Compute Units
- Each Compute Unit is composed of one or more Processing Elements
- Memory is divided into host memory and device memory
How many devices are available?
The omp_get_num_devices routine returns the number of target devices.
#include <stdio.h>
#include <omp.h>
int main()
{
int num_devices = omp_get_num_devices();
printf("Number of devices: %d\n", num_devices);
}
Compile with gcc/9.3.0:
module load gcc/9.3.0
gcc device_count.c -fopenmp -odevice_count
Run it on the login node. How many devices are available on the login node?
Then run it on a GPU node:
srun --gpus-per-node=1 ./device_count
Request two GPUs. How many devices are detected now?
How to offload to a GPU?
- Identify routines (compute kernels) suitable for accelerators.
- Explicitly express parallelism in the kernel.
- Manage data transfer between CPU and Device.
Example: compute sum of two vectors.
Start from the serial code vadd_gpu_template.c.
/* Compute sum of vectors A and B */
#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
int main(int argc, char *argv[])
{
double start, end;
int size = 1e8;
float *A;
float *B;
float *C;
double sum = 0.0f;
int ncycles=atoi(argv[1]);
A = (float *)malloc(size * sizeof(float *));
B = (float *)malloc(size * sizeof(float *));
C = (float *)malloc(size * sizeof(float *));
/* Initialize vectors */
for (int i = 0; i < size; i++)
{
A[i] = (float)rand() / RAND_MAX;
B[i] = (float)rand() / RAND_MAX;
}
start = omp_get_wtime();
for (int k = 0; k < ncycles; k++)
for (int i = 0; i < size; i++)
{
C[i] = A[i] + B[i];
sum += C[i];
}
end = omp_get_wtime();
printf("Time: %f seconds\n", end - start);
sum = sum / size;
printf("Sum = %f\n ", sum / ncycles);
}
gcc vadd_gpu_template.c -fopenmp -O3 -ovadd_serial
In order to get an accurate timing on GPUs, we must run summation multiple times. The number of repeats can be specified on the command line:
srun --gpus-per-node 1 --mem=5000 -c4 ./vadd_serial 10
Execution time of the serial code is around 1.6 sec.
How to Offload: the OpenMP Target Directive
- OpenMP offload constructs were introduced in OpenMP 4.0.
OpenMP target instructs the compiler to generate a target task, which executes the enclosed code on the target device.
Make a copy of the code:
cp vadd_gpu_template.c vadd_gpu.c
Identify code block we want to offload to GPU and generate a target task:
...
for (int k = 0; k < ncycles; k++)
#pragma omp target
for (int i = 0; i < size; i++)
{
C[i] = A[i] + B[i];
sum += C[i];
}
...
Compile and run on a GPU node:
gcc vadd_gpu.c -fopenmp -O3 -ovadd_gpu
srun --gpus-per-node 1 --mem=5000 -c4 ./vadd_gpu 10
libgomp: cuCtxSynchronize error: an illegal memory access was encountered
The compiler created target task and offloaded it to a GPU, but the data is on the host!
Moving Data Between Hosts and Devices: the OpenMP Map Directive.
map(map-type: list[0:N])
- map-type may be to, from, tofrom, or alloc. The clause defines how the variables in list are moved between the host and the device.
...
for (int k = 0; k < ncycles; k++)
#pragma omp target map(to: A[0:size],B[0:size]) map(from: C[0:size])
for (int i = 0; i < size; i++)
{
C[i] = A[i] + B[i];
sum += C[i];
}
...
Compile and run on a GPU node:
gcc vadd_gpu.c -fopenmp -O3 -ovadd_gpu
srun --gpus-per-node 1 --mem=5000 -c4 ./vadd_gpu 1
Execution time of the offloaded code is slower, around 8 sec. It is expected because:
- By using the
omp targetdirective, a target task is created, offloaded to the GPU, but is not parallelized. It executes on a single thread. - The processors on GPUs are slower than the CPUs.
- It takes some time for data to be transferred from the host to the device.

The OpenMP Teams directive.
teamsconstruct creates a league of teams.- the master thread of each team executes the code
Using the teams construct is the first step to utilizing multiple threads on a device. A teams construct creates a league of teams. Each team consists of some number of threads, when the directive teams is encountered the master thread of each team executes the code in the teams region.
...
for (int k = 0; k < ncycles; k++)
#pragma omp target teams map(to: A[0:size],B[0:size]) map(from: C[0:size])
for (int i = 0; i < size; i++)
{
C[i] = A[i] + B[i];
sum += C[i];
}
...
Compile and run on a GPU node:
gcc vadd_gpu.c -fopenmp -O3 -ovadd_gpu
srun --gpus-per-node 1 --mem=5000 -c4 ./vadd_gpu 1
Execution time is the same!
Now we have multiple threads executing on the device, however they are all performing the same work.

It is also important to note that only the master thread for each team is active.
Review
Right now we have:
- Multiple thread teams working on a device
- All thread teams are performing the same work
- Only the master thread of each team is executing
The OpenMP Distribute directive.
The distribute construct can be used to spread iterations of a loop among teams.

...
for (int k = 0; k < ncycles; k++)
#pragma omp target teams distribute \
map(to: A[0:size],B[0:size]) map(from: C[0:size])
for (int i = 0; i < size; i++)
{
C[i] = A[i] + B[i];
sum += C[i];
}
...
Compile and run on a GPU node:
gcc vadd_gpu.c -fopenmp -O3 -ovadd_gpu
srun --gpus-per-node 1 --mem=5000 -c4 ./vadd_gpu 1
Execution time is faster, about 1 sec, but how it compares with the CPU version?
gcc vadd_gpu_template.c -O3 -fopenmp -ovadd_serial
srun --mem=5000 -c4 ./vadd_serial 1
This is disappointing, serial version running on a single CPU is 5 times faster!
The master thread is the only one we have used so far out of all the threads available in a team!
At this point, we have teams performing independent iterations of this loop, however each team is only executing serially. In order to work in parallel within a team we can use threads as we normally would with the basic OpenMP usage. Composite constructs can help.
The distribute parallel for construct specifies a loop that can be executed in parallel by multiple threads that are members of multiple teams.
...
for (int k = 0; k < ncycles; k++)
#pragma omp target teams distribute \
parallel for \
map(to: A[0:size],B[0:size]) map(from: C[0:size])
for (int i = 0; i < size; i++)
{
C[i] = A[i] + B[i];
sum += C[i];
}
...
Compile and run on a GPU node:
gcc vadd_gpu.c -fopenmp -O3 -ovadd_gpu
srun --gpus-per-node 1 --mem=5000 -c4 ./vadd_gpu 1

Now, we have teams splitting the work into large chunks on the device, while threads within the team will further split the work into smaller chunks and execute in parallel.
We have two problems:
- It did not take less time to execute.
- The sum is not calculated correctly.
Maybe the work is not large enough for the GPU? To increase the amount of calculations, we could repeat the loop multiple times. Try running 20 cycles of addition. Did the execution time increase 20 times? It took only 7 seconds instead of the expected 20 seconds. We are on the right track, but what else can be improved in our code to make it more efficient?
The OpenMP Target Data directive.
Each time we iterate, we transfer data from the host to the device, and we pay a high cost for data transfer. Arrays A and B can only be transferred once at the beginning of calculations, and the results can only be returned to the host once the calculations are complete. The target data directive can help with this.
The target data directive maps variables to a device data environment for the extent of the region.
...
#pragma omp target data map(to: A[0:size], B[0:size]) map(from: C[0:size])
for (int k = 0; k < ncycles; k++)
#pragma omp target teams distribute \
parallel for \
map(tofrom: sum)
for (int i = 0; i < size; i++)
{
C[i] = A[i] + B[i];
sum += C[i];
}
...
Compile and run on a GPU node for 20 cycles:
gcc vadd_gpu.c -fopenmp -O3 -ovadd_gpu
srun --gpus-per-node 1 --mem=5000 -c4 ./vadd_gpu 20
The time decreased from 7 to 1 sec! Try running for 100 cycles. Did the time increase proportionally to the work?
Let’s take care of issue with sum.
We get the wrong result with sum, it is zero, so it looks like it is not transferred back from the device.
...
#pragma omp target data map(to: A[0:size], B[0:size]) map(from: C[0:size])
for (int k = 0; k < ncycles; k++)
#pragma omp target teams distribute \
parallel for \
map(tofrom: sum) reduction(+:sum)
for (int i = 0; i < size; i++)
{
C[i] = A[i] + B[i];
sum += C[i];
}
...
We need to add a reduction clause and map sum tofrom the device since we parallelized the for loop.
Using Nvidia HPC compiler
Nvidia HPC compiler generates faster binary, but it does not run on the training cluster.
module load nvhpc/22.7
nvc vadd_gpu.c -O3 -fopenmp -mp=gpu -Minfo=mp
nvc vadd_gpu.c -O3 -fopenmp -mp=multicore -Minfo=mp
Getting info about available GPUs
Using the nvidia-smi command
nvidia-smi --query-gpu=timestamp,utilization.gpu,utilization.memory -format=csv -l 1 >& gpu.log&
Using OpenMP functions
#include <stdio.h>
#include <omp.h>
int main()
{
int nteams, nthreads;
int num_devices = omp_get_num_devices();
printf("Number of available devices %d\n", num_devices);
#pragma omp target teams defaultmap(tofrom : scalar)
{
if (omp_is_initial_device())
printf("Running on host\n");
else
{
nteams = omp_get_num_teams();
#pragma omp parallel
#pragma omp single
if (!omp_get_team_num())
{
nthreads = omp_get_num_threads();
printf("Running on device with %d teams x %d threads\n", nteams, nthreads);
}
}
}
}
Compile with gcc/9.3.0:
module load gcc/9.3.0
gcc get_device_info.c -fopenmp -ogpuinfo
srun --gpus-per-node=1 --mem=1000 ./gpuinfo
With gcc/11 you will get 216 teams x 8 threads (Quadro RTX 6000)
Compile with nvidia compiler:
module load nvhpc/22.7
nvc get_device_info.c -mp=gpu -ogpuinfo
srun --gpus-per-node=1 --mem=1000 ./gpuinfo
With nvhpc you’ll get 72 teams x 992 threads on the same GPU.
Parallelizing with OpenACC
cp vadd_gpu_template.c vadd_gpu_acc.c
The acc kernels Construct
Let’s add a single, simple OpenACC directive before the block containing for loop nest.
#pragma acc kernels
This pragma tells the compiler to generate parallel accelerator kernels (CUDA kernels in our case).
Compiling with Nvidia HPC SDK
Load the Nvidia HPC module:
module load StdEnv/2020 nvhpc/22
To compile the code with OpenACC we need to add the -acc flag
nvc vadd_gpu_acc.c -O3 -acc
Let’s run the program. It runs slow compared even to our serial CPU code.
Were the loops parallelized?
- enable printing information about the parallelization ( add the option -Minfo=accel) and recompile
nvc vadd_gpu_acc.c -O3 -acc -Minfo=accel
33, Generating implicit copyin(A[:100000000],B[:100000000]) [if not already present]
Generating implicit copy(sum) [if not already present]
Generating implicit copyout(C[:100000000]) [if not already present]
35, Complex loop carried dependence of B->,A-> prevents parallelization
Loop carried dependence due to exposed use of C prevents parallelization
Complex loop carried dependence of C-> prevents parallelization
Accelerator serial kernel generated
Generating NVIDIA GPU code
35, #pragma acc loop seq
36, #pragma acc loop seq
35, Complex loop carried dependence of C-> prevents parallelization
36, Complex loop carried dependence of B->,A->,C-> prevents parallelization
The __restrict Type Qualifier
Our data arrays (A, B, C) are dynamically allocated and are accessed via pointers. Pointers may create data dependency because:
- More than one pointer can access the same chunk of memory in the C language.
- Arithmetic operations on pointers are allowed.
Using the __restrict qualifier to a pointer ensures that it is safe and enables better optimization by the compiler.
float * __restrict A;
float * __restrict B;
float * __restrict C;
After this modification The compiler parallelizes the loop and even automatically determines what data should be copied to the device and what reduction operations are needed.
- It is important to examine optimixzation reports
- It is best to add explicit data transfer direcives and reduction clauses to ensure your program will work correctly when compiled with different compilers.
Key Points
OpenMP offers a quick path to accelerated computing with less programming effort