Using blocks instead of threads
Overview
Teaching: 10 min
Exercises: 20 minQuestions
What is the difference between blocks and threads?
Is one faster than the other?
Objectives
To use blocks to parallelize work
Examine CUDA performance
In the Hello World example we saw the <<<M,N>>> syntax used in CUDA to call a
kernel function, and we told you that it creates M blocks and N threads per
block. In the Adding Vectors example we just finished, we created threads with
<<<1,N>>>. Now we will use the first parameter to create blocks instead.
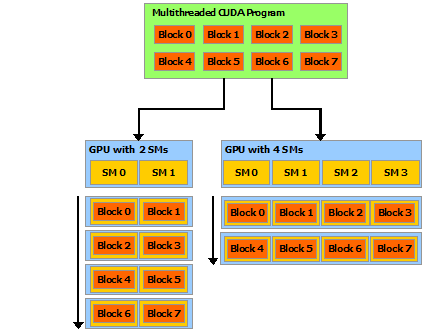
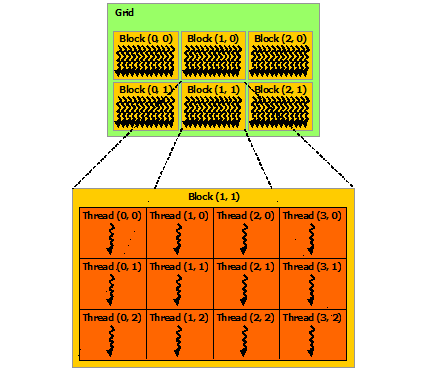
What’s a block? A GPU typically has several streaming multiprocessors (SMs). A block is handled by one SM, and each SM may handle many blocks in succession. Each SM supports up to 1024 threads, typically in multiples of 32 called “warps”. Threads can quickly access and share the data within a block. The pictures below from CUDA C Programming Guide should help:
| Blocks and SMs | Thread Blocks |
|---|---|
 |
 |
The P100 GPU model available at Graham Cedar has 56 SMs, each supporting 64 single-precision threads or 32 double-precision threads. So if you are doing double-precision calculations, each GPU has effectively 56*32 = 1792 cores. At Béluga there are newer V100 GPUs with 80 SMs, which again support 64 single-precision or 32 double-precision threads each, for 2560 effective cores.
But to take advantage of all these “CUDA cores” you need to use both blocks and threads.
We’ll start by doing something a little silly, and just switch from threads to
blocks. Change the kernel function to use CUDA’s block index,
blockIdx.x, like so:
__global__ void add(int *a, int *b, int *c) {
c[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];
}
Exercise: Change threads to blocks
Copy the Adding Vectors example you just finished, and change the copy to use blocks instead of threads. Verify that it still produces correct results.
Solution
#include <stdio.h> #include <stdlib.h> __global__ void add(int *da, int *db, int *dc) { dc[blockIdx.x] = da[blockIdx.x] + db[blockIdx.x]; } int main(int argc, char **argv) { int a_in = atoi(argv[1]); // first addend int b_in = atoi(argv[2]); // second addend int N = atoi(argv[3]); // length of arrays int numBlocks = 512; int *a, *b, *c; int *d_a, *d_b, *d_c; int size = N * sizeof(int); a = (int *)malloc(size); b = (int *)malloc(size); c = (int *)malloc(size); // Initialize the input vectors for (int i=0; i<N; ++i) { a[i] = a_in; b[i] = b_in; c[i] = 0; } cudaMalloc((void **)&d_a, size); cudaMalloc((void **)&d_b, size); cudaMalloc((void **)&d_c, size); cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice); cudaMemcpy(d_b, b, size, cudaMemcpyHostToDevice); add<<<numBlocks,1>>>(d_a, d_b, d_c); cudaDeviceSynchronize(); cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost); cudaFree(d_a); cudaFree(d_b); cudaFree(d_c); printf("%d + %d = %d\n", a[0], b[0], c[0]); printf("...\n"); printf("%d + %d = %d\n", a[N-1], b[N-1], c[N-1]); free(a); free(b); free(c); }
Measuring speed
The point of using a GPU is speed, so how do we measure the speed of
our kernel code and the various CUDA calls like cudaMemcpy? CUDA
provides the utility nvprof for this. Here’s some sample output:
$ nvprof ./addvec_blocks 1 2 512
==6473== NVPROF is profiling process 6473, command: ./addvec_blocks
==6473== Profiling application: ./addvec_blocks
1 + 2 = 3
...
1 + 2 = 3
==6473== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 39.36% 3.1360us 2 1.5680us 1.3440us 1.7920us [CUDA memcpy HtoD]
38.96% 3.1040us 1 3.1040us 3.1040us 3.1040us add(int*, int*, int*)
21.69% 1.7280us 1 1.7280us 1.7280us 1.7280us [CUDA memcpy DtoH]
API calls: 99.20% 191.29ms 3 63.765ms 9.4530us 191.27ms cudaMalloc
0.35% 681.62us 1 681.62us 681.62us 681.62us cuDeviceTotalMem
0.21% 413.84us 96 4.3100us 108ns 167.14us cuDeviceGetAttribute
0.08% 158.83us 3 52.942us 4.9910us 139.28us cudaFree
0.07% 136.64us 1 136.64us 136.64us 136.64us cudaLaunchKernel
0.05% 90.485us 3 30.161us 14.610us 58.564us cudaMemcpy
0.03% 52.872us 1 52.872us 52.872us 52.872us cuDeviceGetName
0.01% 11.735us 1 11.735us 11.735us 11.735us cudaDeviceSynchronize
0.00% 3.5890us 1 3.5890us 3.5890us 3.5890us cuDeviceGetPCIBusId
0.00% 1.4540us 3 484ns 120ns 923ns cuDeviceGetCount
0.00% 651ns 2 325ns 189ns 462ns cuDeviceGet
0.00% 204ns 1 204ns 204ns 204ns cuDeviceGetUuid
This tells us the GPU spent 3.1040 microseconds in our add() kernel,
but spent slightly longer (3.1360us) just copying the data from the
host to the device, and then half that again copying the results back.
You might also note that, among the “API calls”, cudaMalloc takes 99%
of the time!
This should drive home what we meant when we said the GPU is for arithmetically intense operations. All the examples we’ve done in this workshop are too small. They could have been done just as quickly and even more simply on the CPU— but that is often the nature of example problems!
Getting your data on to and off of the GPU is the price you pay to access the massive parallelism of the GPU. To make that worth while, you have to need to do a lot of arithmetic! And your program should be designed in such a way that data movement between main memory and GPU is minimized. Ideally the data moves onto the GPU once, and moves off once.
Nonetheless, as long as you bear in mind which parts of these problems are
artificial, you can still use nvprof to answer some interesting questions, like,
“Is it faster to use threads or blocks?”
Speed trial: Threads versus blocks
Compare the performance of the
add()kernel in the two codes you just produced. Which is faster, using threads or using blocks? How much faster?What happens if you vary the size of the array? Make sure you still get correct answers!
Key Points
Use
nvprofto profile CUDA functionsBlocks are the batches in which a GPU handles data
Blocks are handled by streaming multiprocessors (SMs)
Each block can have up to 1024 threads (on our current GPU cards)